bnbdr
YARA Internals II: Bytecode
and how it can still be used to run arbitrary code
Dec 4, 2018
Unlike my fastidious explanation of YARA’s binary rule format, I’ll try to keep this post short by focusing on YARA’s VM architecture and how a compiled rule can still be used to run arbitrary code, despite the mitigations added to the latest release of YARA1.
The issues I’d discovered were assigned CVE-2018-19974, CVE-2018-19975 and CVE-2018-19976.
To skip straight to the exploitation part jump here, head over to the repo or the GitHub issue.
YARA’s Virtual Machine
YARA’s virtual machine (henceforth referenced as yvm for brevity) uses a stack2 (vstack) and has a small scratch memory (vmem). All operations of the bytecode use QWORD values (yval). The virutal machine also supports branching, arithmic operations, etc (implemented in exec.c).
yvm allocates a pretty big virtual stack by default (0x4000 bytes). This size is configurable by passing stack-size as a command-line argument.
Most opcodes either explicitly or implicitly push or pop off the vstack, changing the stack-pointer (sp) accordingly. When the opcode OP_HALT is reached yvm asserts the vstack is empty (sp == 0).
Contrary to the virtual stack, vmem is placed on the real stack and is quite small - holding only 16 yvals. Accessing this memory region is possible using OP_PUSH_M and OP_POP_M(amongst others). Both of which use the vstack as target or source and have one operand that specifies the index in vmem to access.
yvm has a None equivalent known as UNDEFINED (which equals 0xFFFABADAFABADAFF) to differentiate between “Falsy” and UNDEFINED cases. This is used for “fail” cases like converting strings to numbers, dividing by zero, etc.
types
To fully support all of YARA’s features, the bytecode has several different core types of yvals:
int64
double
pointer
object
match-string
string
regex
Out of the above, most noteworthy is the object type which corresponds to the YR_OBJECT struct in YARA’s implementation. This is used to support “named” objects (yobj) that are exposed by yvm and its modules3, and fall between the following “class” types:
| class | exposed functionality | opcode | yara rule example |
|---|---|---|---|
| structure | fetch member yobj by name | OP_OBJ_FIELD | pe.number_of_sections |
| dictionary | fetch yobj by name | OP_LOOKUP_DICT | pe.version_info["CompanyName"] |
| array | fetch yobj at index | OP_INDEX_ARRAY | dotnet.streams[i] |
yval wrapper | fetch yobj’s yval | OP_OBJ_VALUE | pe.number_of_sections == 1 |
| function | peform action with yval list | OP_CALL | pe.imports("LoadLibrary") |
Before performing any of the above the bytecode must load the yobj to the stack using OP_OBJ_LOAD. To check pe.number_of_sections the bytecode would have to do something like this:
OP_OBJ_LOAD ascii "pe"
# stack: [pe<yobj>]
OP_OBJ_FIELD ascii "number_of_sections"
# stack: [number_of_sections<yobj>]
OP_OBJ_VALUE
# stack: [1<yval>]
...
modules
If you go ahead and disassemble4 the following rule you’ll notice a few extra opcodes were generated compared to the above yarasm5:
import "pe"
rule single_section
{
condition:
pe.number_of_sections == 1
}
One of them is OP_IMPORT. It tells yvm to load the "pe" module- otherwise OP_OBJ_LOAD would fail to locate a yobj with that identifier. At this point yvm hands over the heavylifting to yr_modules_load where the loading logic is performed in two steps:
- declarations: creating a tree of “named” objects (
yobjs) for theyvmruntime. - parsing: iterating over the input to be scanned and initializing the relavant
yobjs that were decalred in the previous step.
Basically, all the yobs declared in the declarations step can now be “found” by OP_OBJ_LOAD.
functions
yvm allows its modules to “export” functions for the bytecode to call. Just like any other yobj, function-class yobjs are found in the same manner. The only difference as far as the bytecode goes is using them.
As noted by the docs, YARA allows function overloading:
begin_declarations;
/* code
ret-val |
arg-list | |
name | | |
V V | V */
declare_function("md5", "ii", "s", data_md5);
declare_function("md5", "s", "s", string_md5);
end_declarations;
Therefore, whenever OP_CALL is encountered yvm will check the length of the arg-list format (the operand) and pop yvals from the vstack to an args array (limited to 128 yvals). yvm will then use the next yval off the vstack as a function-yobj and search it for the matching prototype.
“PARANOID_EXEC”
YARA version 3.8.1 introduced PARANOID_EXEC to mitigate maliciously compiled bytecode (with added checks on the rule file itself too). Most importantly it added:
- boundry checks on all opcodes that access
vmem - boundry checks before writing to
argsarray (which is on the real stack) - extra checks on
vstackboundries - a canary in every
yobjcreated byyvm, randomized when YARA is initialized.
The paranoid is never entirely mistaken
This too started with pure intentions. I wish to contribute a feature to YARA; one I couldn’t implement without looking carefully at YARA’s modules with regards to their life-cycle and their interaction with the bytecode.
CVE-2018-19976
Only after some time did it hit me - the entire concept of loading a yobj to the stack is itself an info-leak, by design. And due to the architecture of yvm I could change that pointer however I liked using arithmic opcodes to point someplace else, hopefully user-controlled.
Even if I leave it to chance ASLR and hope for the best, almost all the promising opcodes check the canary and the class type of the yobj before touching it, making it literally impossible.
CVE-2018-19975
Cue in OP_COUNT:
// no checks here
r1.i = r1.s->matches[tidx].count;
Which to those less familiar with YARA code, loosly6 translates to:
*TOS <-- *(UINT_PTR)(*TOS+0x38)
CVE-2018-19974
To top it all of, I realized that vmem was uninitalized, leaking some more addresses (but not necessary for my PoC).
It hurt itself in its confusion
I’d set onwards to write a PoC exploit. The master plan was building a fake function yobj on the vstack. To make sure it works I had to set the overload prototype for the function, point the code to a gadget, populate the leaked canary, and then make YARA use that fake yobj to my advantage by executing OP_CALL.
There was one lingering issue - where exactly is the vstack?
Before I started skimming through the available leaked values in the uninitalized vmem, I remembered OP_IMPORT causes a lot of allocations and I can control when. Long story short, the vstack is reliably positioned 0x20450(or 0x20490 if debugging in VS) behind the "pe" module7.
So now I got a lovely fake yobj whose “function” address will be called using the following prototype:
typedef int (*OP_CALL_TARGET)(void*, void*, void*);
There was still the matter of building and placing a ROP chain. As for building- getting to a real function yobj is really easy with OP_OBJ_LOAD/OB_OBJ_FIELD. And since all of YARA’s modules are statically compiled I can easily infer YARA’s base address by “loading” an existing function yobj.
Ironically, the largest buffer under my control that’s also placed on the real stack is the args array. By setting a large enough arg-list format for my fake function yobj I can populate it with up to 128 yvals - 256 gadgets! The only thing missing is that first gadget to start it all- to return right into my args array. Luckily finding a rogue add esp, 0XXh; ret was easy enough.
At this point I felt pleased with my PoC and settled on locating WinExec by calculating its offset7 from GetProcAddress, which is imported by YARA.
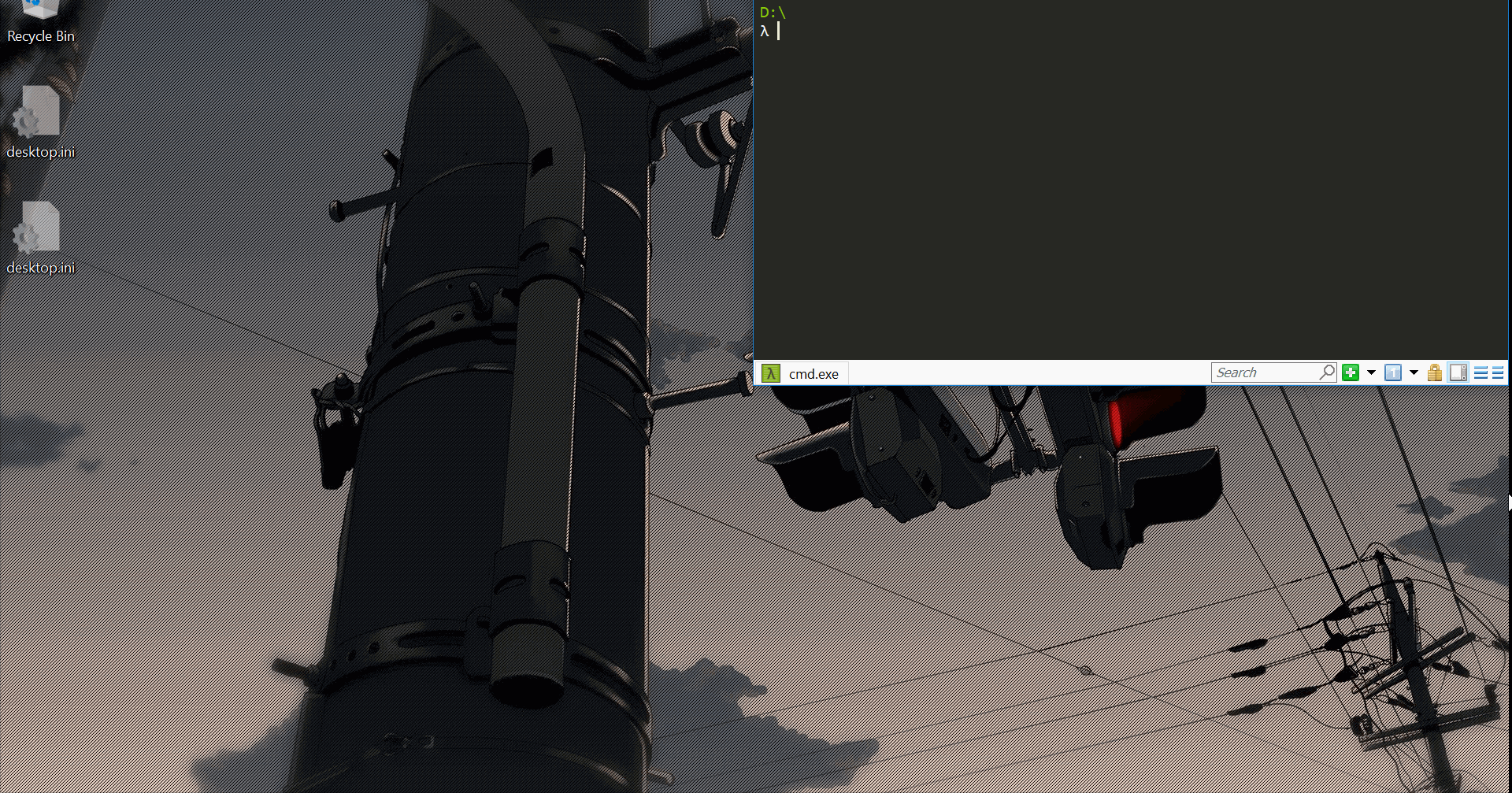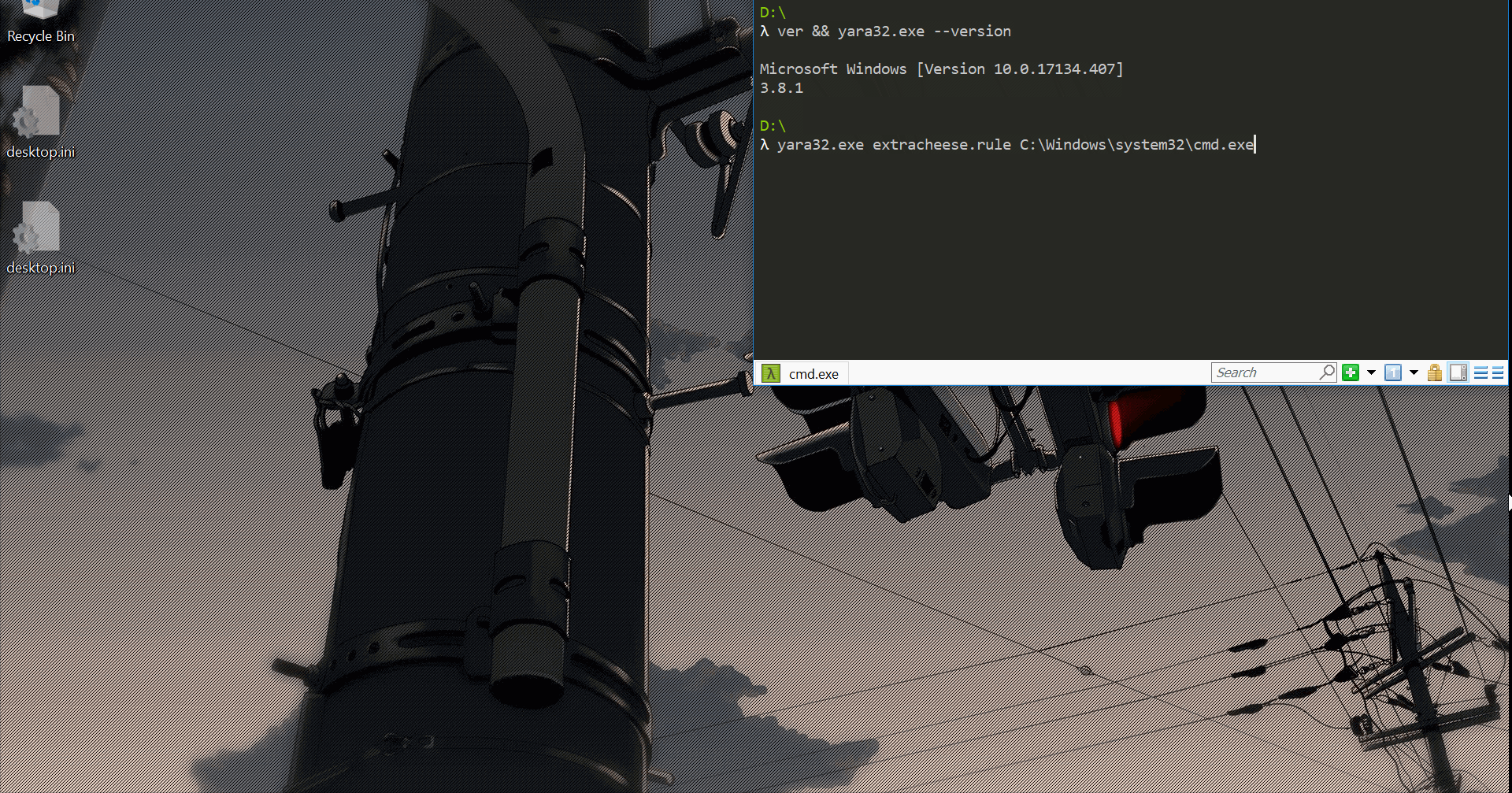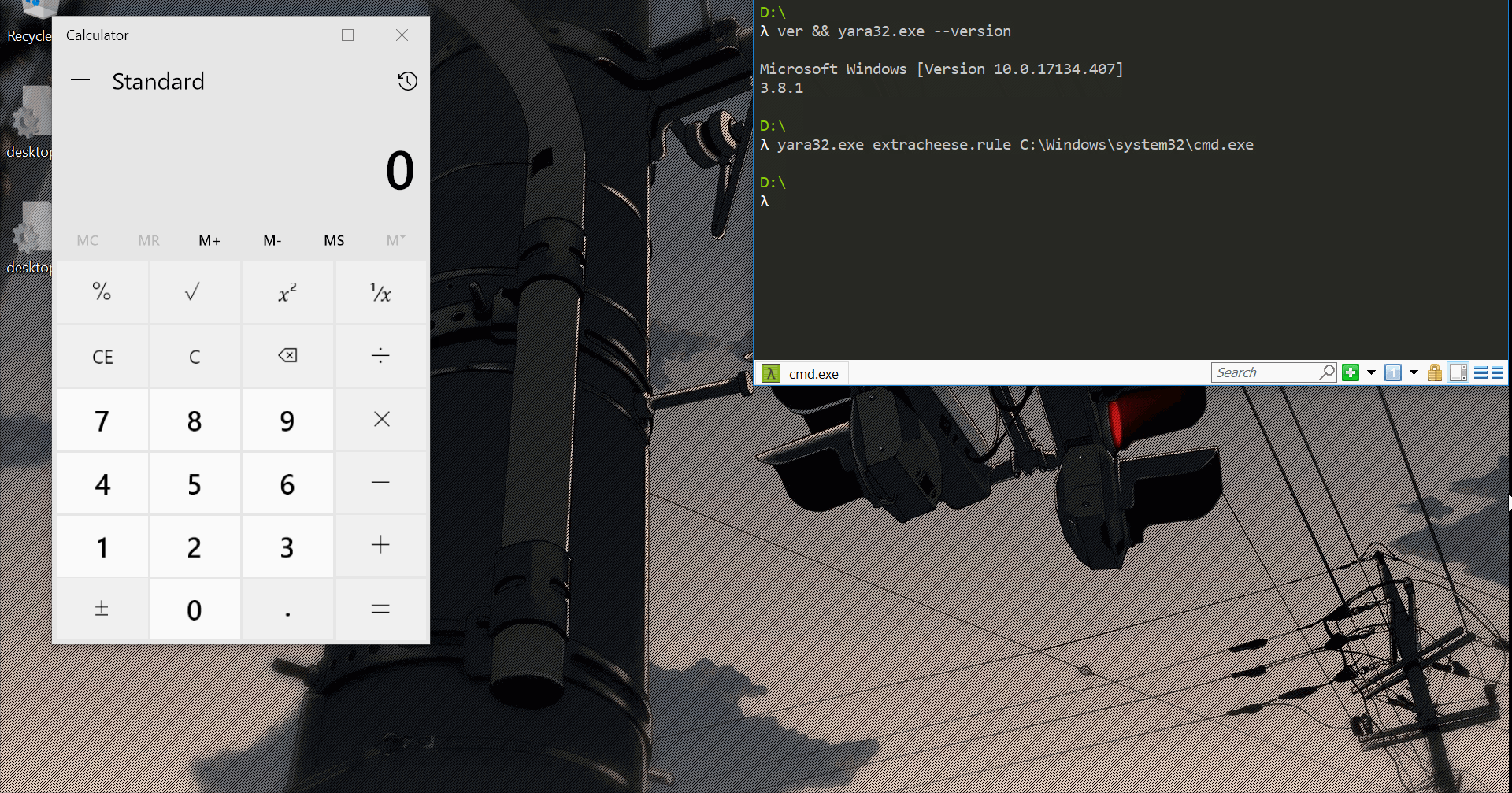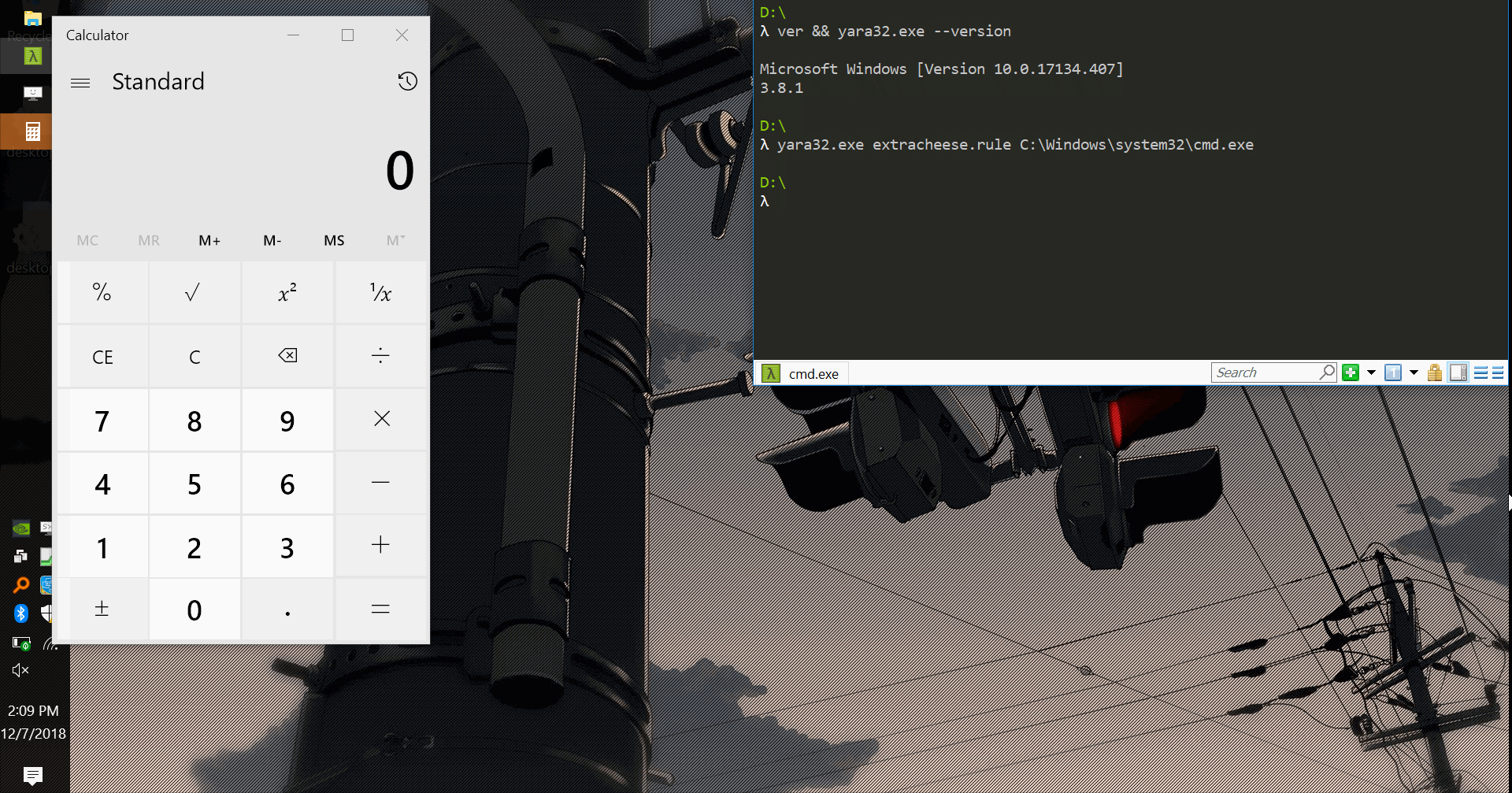
Epilogue
I tried making the yara assembly code for this exploit as readable as possible and wrote a syntax highlighting extension for VSCode. I encourage those curious to take a look.
- this research was done on 32-bit yara 3.8.1 from the official release page ↑
- https://en.wikipedia.org/wiki/Bytecode ↑
- https://yara.readthedocs.io/en/latest/modules.html ↑
- you can use the 010template, or for the lazy ↑
- name I coined for YARA’s assembly language ↑
- depends on the thread index (always 0 when scanning a single file) ↑
- on my machine, Windows 10.0.17134 64bit (WoW64) ↑
{kind=link}