bnbdr
YARA Internals: Compiled Rule Format
and how to exploit The Pattern Matching Swiss Knife
Jun 6, 2018
(updated: Dec 4, 2018)
(updated: Dec 4, 2018)
Cheese, Gromit
In this short incredibly lengthy post I’ll talk about the binary format of YARA rules and also a bit about exploiting two vulnerabilities I found in it.
The two issues were assigned the CVE-IDs CVE-2018-12034 and CVE-2018-12035. They affect YARA 3.7.1 and earlier1.
If you want to skip straight to the exploitation part, go to WAT or take a look at the repo.
I named this SwissCheese becuase I found it amusing that the “Pattern Matching Swiss Knife” had quite a few holes in it ;D
Precompiling YARA rules
Most people who use it know that YARA accepts rule(s) and a target, and also that you can precompile2 your rule if you care about “performance”. I was a bit curious about the precompiled part. How is my rule represented in its binary form? I took the simplest of rules:
rule empty {
condition: true
}
and compiled to ~21KB of, what exactly? I’ll come back to the size issue, so let’s take a look at the code first.
Haystack, meet needle
As an aside, I have to commend the YARA developers for making the setup effortless - having a Visual Studio solution that compiles was a refreshing and welcome feeling.
However, trying to understand the file format wasn’t as straightforward. I didn’t want to understand everything YARA does, nor everything about the file format - the gist was enough.
A reasonable idea is to look for either the loading or packing of the file in order to understand the format.
That’s where ‘magic’ strings come into play. They often act like bookmarks- searching the code for the string either in reverse or not (depending on endianness, etc) will usually yield results:
![]()
- unpacking in yara32:
main -> yr_rules_load -> yr_rules_load_stream - packing in yarac32:
main -> yr_rules_save -> yr_rules_save_stream
if (header.magic[0] != 'Y' ||
header.magic[1] != 'A' ||
header.magic[2] != 'R' ||
header.magic[3] != 'A')
{
return ERROR_INVALID_FILE;
}
I’ll be focusing on yr_arena_load_stream since it’s logically the same thing I’m trying to mimic.
Off to a buggy start
The format, unsurprisingly, starts with a header containing a magic, version and size of the remaining file(kinda). After some basic yet buggy validation yara reads the body of the file and performs relocations. Yeah, apparently precompiling it mostly means dumping the memory-transient buffer to disk after converting absolute addresses to file offsets.
That meant the tail of the file (whatever’s left after the number written in the file header) was a relocation table. Yara then checks each offset if it actually requires patching:
- if the
QWORDvalue in that offset was different than0xFFFABADAit should be patched - Otherwise it should be set to
NULL
I’m not sure why it uses that magic instead of omitting that relocation from the table in the first place.
To tell yara it’s reached the end of the table it uses a special marker: 0xFFFFFFFF. Following it is another DWORD which is the calculated hash for the file.
Hash whiplash
The hash isn’t very interesting3. Yara first hashes the file header, then uses it as a seed to the hashing of the body. Note that the hashing is performed before the patching, because the ‘compiler’ obviously can’t predict the allocated address used for the file.
I’m ready for you
Now that the buffer is all patched up, we can really get into it. Let’s jump to yr_rules_load_stream to see what’s going on with our newly relocated file body.
Thanks to some initialization and casting being done we can discern an additional chunk of the format: It starts with a rule header, alligned to 8; I suppose it’s so the same precompiled rules would work on both 32 and 64 bit builds (sizeof(PVOID) etc), but I’m not sure why it’s all that important.
The macro DECLARE_REFERENCE basically makes everything a QWORD. All the members you see below that are not pointers are actually typedef’d to one:
typedef struct _YARA_RULES_FILE_HEADER
{
DECLARE_REFERENCE(YR_RULE*, rules_list_head);
DECLARE_REFERENCE(YR_EXTERNAL_VARIABLE*, externals_list_head);
DECLARE_REFERENCE(const uint8_t*, code_start);
DECLARE_REFERENCE(YR_AC_MATCH_TABLE, match_table);
DECLARE_REFERENCE(YR_AC_TRANSITION_TABLE, transition_table);
} YARA_RULES_FILE_HEADER;
With the knowledge that every pointer shown above is actually present in the file as an offset(minus the size of the first header) is a great step forward. I’m slowly crawling my way through the file.
I make the rules
The first member in our rule-header is a fointer (not a typo, stands for ‘File Pointer’; I will be using this from now on so deal with it) to a rule struct:
typedef struct _YR_RULE
{
int32_t g_flags; // Global flags
int32_t t_flags[MAX_THREADS]; // Thread-specific flags
DECLARE_REFERENCE(const char*, identifier);
DECLARE_REFERENCE(const char*, tags);
DECLARE_REFERENCE(YR_META*, metas);
DECLARE_REFERENCE(YR_STRING*, strings);
DECLARE_REFERENCE(YR_NAMESPACE*, ns);
// Used only when PROFILING_ENABLED is defined
clock_t clock_ticks;
} YR_RULE;
You should hastily recognize some fointers in the above struct as optional parts in a rule: identifier, tags, metas,strings, namespace. At this point I noticed the pattern and started copying all the relevant structs to my template4. Every fointer that isn’t equal to 0xFFFABADA means seeking to that position and parsing the struct there, ad infinitum.
In the case of our empy rule, which had no tags, metas or strings, only the identifier and ns members are of interest.
You’d be right to think “hey, but what if we have more than one rule in our source file?”. If you looked carefully at the member rules_list_head you’d guess that, going by its name, it points to the first rule. How does yara know where the other ones are? Let’s follow the code and see when the rules are actually being used, ignoring everything else for now:
main -> yr_rules_scan_file -> yr_rules_scan_mem -> yr_rules_scan_mem_blocks : yr_rules_foreach
Peeking at the macro, I figured two things:
- the rules are placed in sequantal order in the file
- the list of rules is terminated by a ‘null rule’
What’s a ‘null rule’?
#define RULE_IS_NULL(x) \
(((x)->g_flags) & RULE_GFLAGS_NULL)
Searching for RULE_GFLAGS_NULL shows it’s being set in _yr_compiler_compile_rules, and also what those mysterious 0xFA bytes were right after the first rule:
// Write a null rule indicating the end.
memset(&null_rule, 0xFA, sizeof(YR_RULE));
null_rule.g_flags = RULE_GFLAGS_NULL;
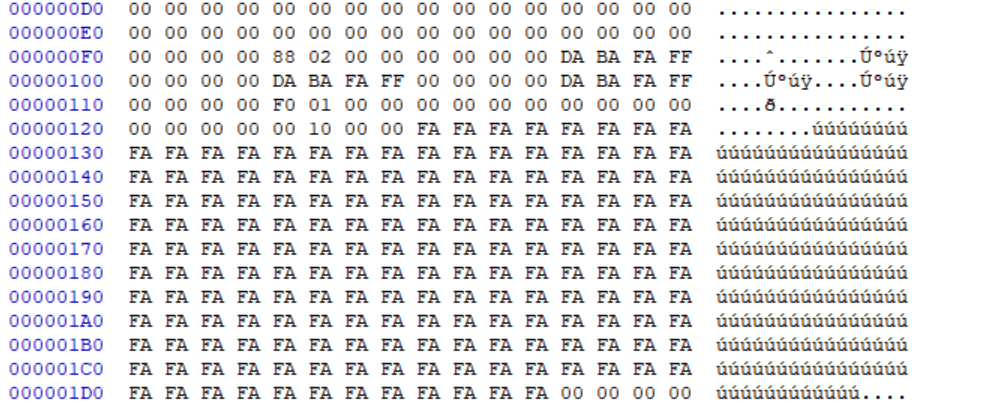
All that’s left to understand in the YR_RULE struct is YR_NAMESPACE. It’s quite short. The only thing of interest is the fointer to the namespace name, which when left unspecified is default:
typedef struct _YR_NAMESPACE
{
int32_t t_flags[MAX_THREADS]; // Thread-specific flags
DECLARE_REFERENCE(char*, name);
} YR_NAMESPACE;
All about alignment
I’m sure you’ve been following along using your favorite hex-editor5 and already know - all the QWORD members (and structs which contain them) should be aligned to an 8-byte boundry seeing that the file is practically a memory map.
Well, you’re right.
DWORDs filled with 0xCC are a good sign for padding in this case. Do note that the file header is 12 bytes long, which means it messes up the alignment when viewed in a hex-editor.
Null-spotting
Going back to _yr_compiler_compile_rules, I couldn’t help spotting that the compiler builds a ‘null external’ right after the ‘null rule’, in a similar fashion:
// Write a null external the end.
memset(&null_external, 0xFA, sizeof(YR_EXTERNAL_VARIABLE));
null_external.type = EXTERNAL_VARIABLE_TYPE_NULL;
Since I didn’t specify any externals6, the externals_list_head in the rule header should point to the ‘null external’, and be done with it. Keep in mind that unlike the ‘null rule’, this is marked by the EXTERNAL_VARIABLE_TYPE_NULL value, which equals 0.
Ready, set, code
Right about here I reached the code_start fointer and forwent my initial interest in the file format. As a fan of virutal machines I was intrigued with the implementation details of the bytecode.
Searching for code_start in the entire solution quickly lands us in yr_execute_code, the proud owner of what can only be decribed as a ‘big-ass switch statement’:
Not unlike the rules/externals, yara keeps exeuting the bytecode until a special marker is reached. In this case the OP_HALT:
while(!stop)
{
opcode = *ip;
ip++;
switch(opcode)
{
case OP_NOP:
break;
case OP_HALT:
assert(sp == 0);
stop = TRUE;
break;
// ...truncated
YARA’s virtual machine
This is a stack based VM with a scratch memory of 128 values. In addition to bitwise, logical and arithmic operations there are several opcodes7 specifically for the vm-stack, as well as the scratch memory.
The VM works with the YR_VALUE union. This way it grabs the appropriate type according to the opcode:
typedef union _YR_VALUE
{
int64_t i;
double d;
void* p;
struct _YR_OBJECT* o;
YR_STRING* s;
SIZED_STRING* ss;
RE* re;
} YR_VALUE;
It’s good to note that since the union may represent a relocated fointer, every immediate in the bytecode has to be 64-bit long.
Disassembly
I started implementing a small disassembler in my template according to the opcodes that were present in my empty rule from earlier. In hindsight I should’ve probably written something in python, but oh well. These were the results:
OP_INIT_RULE
OP_PUSH
OP_INCR_M
OP_NOP
OP_HALT
OP_INIT_RULEseemed a tad complex so I was content with skipping the implementation for the time being.OP_PUSHsimply reads nextYR_VALUEfrom the bytecode, and pushes it on the vm-stackOP_INCR_Mincreases theYR_VALUEin the scratch mem indexed by the next immediate
WAT
All seems quite reasonab- wait, what?
case OP_INCR_M:
r1.i = *(uint64_t*)(ip);
ip += sizeof(uint64_t);
mem[r1.i]++; // < --------- WAT
break;
It was quite a shock. I wasn’t expecting such a trivial security issue, but I had a hunch this wasn’t limited to that one opcode. Scanning through the other opcodes proved me right:
case OP_PUSH_M:
r1.i = *(uint64_t*)(ip);
ip += sizeof(uint64_t);
r1.i = mem[r1.i]; // Out-of-bounds Read
push(r1);
break;
case OP_POP_M:
r1.i = *(uint64_t*)(ip);
ip += sizeof(uint64_t);
pop(r2);
mem[r1.i] = r2.i; // Out-of-bounds Write
break;
The scratch memory mem is placed on the the real stack which means one could easily use both opcodes to read stuff off the stack and write a ROP chain:
int yr_execute_code(
YR_RULES* rules,
YR_SCAN_CONTEXT* context,
int timeout,
time_t start_time)
{
int64_t mem[MEM_SIZE];
...truncated
Building a compiled rule
So the first thing I needed to do to test this thing out was to create a compiled rule with my hand-crafted yara assembly. This isn’t that difficult, all I need to do is:
- read a binary rule as a template
- follow the headers to the code_start
- assemble new code
- inject new code
- update all the
fointersthat point after my code - update the relocation table to the correct offsets
- remove the relocations that pointed to the old code so they won’t alter mine
- patch the file hash
I decided that building a rule from scratch would be easier, or at least less error prone. The most basic test would be rebuilding the empty rule from before on my own.
The size issue
I wanted to tackle the humongous file size at this point. It was a bit annoying and I thought of it as a good test for what I’ve learned so far.
Assuming yara doesn’t care where the fointers point as long as they point to valid data, I opted for placing my code at the end of the file body, which resulted in the following structure:
YR_HDR // file header
YARA_RULES_FILE_HEADER
YR_RULE
YR_RULE // null rule
YR_EXTERNAL_VARIABLE // null external
YR_NAMESPACE
CHAR[] namespace_name
CHAR[] rule_name
YR_AC_MATCH_TABLE
EMPTY_TRANSITION_TABLE
MY_CODE
RELOCATION_TABLE
END_OF_RELOCATION_MARKER
FILE_HASH
Thanks to the fact the relocation table only holds offsets that require relocations (none of that 0xFFFABADA magic) the relocation table is much much smaller.
I didn’t cover the structs YR_AC_MATCH_TABLE and EMPTY_TRANSITION_TABLE until now. I’m pretty sure these are used for the Aho-Corasick algorithm. I tried my best to ignore them.
Getting there is half the fun
Sadly, before we get yara to execute our bytecode in yr_execute_code, we must pass through _yr_rules_scan_mem_block which uses the aforementioned Aho-Corasick structures:
uint16_t index;
uint32_t state = YR_AC_ROOT_STATE;
...
index = block_data[i++] + 1; // <-- block_data is the scanned memory, we can't control it
transition = transition_table[state + index]; // <-- this is troublesome
while (YR_AC_INVALID_TRANSITION(transition, index))
{
if (state != YR_AC_ROOT_STATE)
{
state = transition_table[state] >> 32;
transition = transition_table[state + index];
}
else
{
transition = 0;
break;
}
}
state = transition >> 32; // <-- we must make sure state remains 0
}
match = match_table[state].match; // <-- this is troublesome as well
In short: we can successfully execute this function as long as the state variable is kept at 0 and transition remains smaller than MAX_UINT.
transition is read from the transition_table, which apparently has MAX_UBYTE+1 64-bit entries.
To ascertain the above I have a full EMPTY_TRANSITION_TABLE filled with 0s, as well as one-entry YR_AC_MATCH_TABLE which is zero’d as well.
After all this I got a valid rule file that’s only ~3KB in size.
The great escape
Finally I can start working on exploiting the vulnerabilities. There are a few small caveats to keep in mind:
- I can only read and write in 64 bit chunks
- I can only read/write as offset from the stack
- I don’t know where my bytecode is
- I can’t overwrite a lot of the real stack due to arguments that are used during cleanup, before the function returns
The 4th caveat is the only real issue. yr_modules_unload_all is called during cleanup. The function uses context->objects_table and would crash if that pointer is overwritten because the context struct is allocated on the stack as well.
typedef struct _YR_SCAN_CONTEXT
{
uint64_t file_size;
uint64_t entry_point;
int flags;
int tidx;
void* user_data;
YR_MEMORY_BLOCK_ITERATOR* iterator;
YR_HASH_TABLE* objects_table; // <-- mustn't touch this
YR_CALLBACK_FUNC callback;
YR_ARENA* matches_arena;
YR_ARENA* matching_strings_arena;
} YR_SCAN_CONTEXT;
The pointer context itself doesn’t suffer from the same problem because the compiler saved it as a local and uses that when calling yr_modules_unload_all:
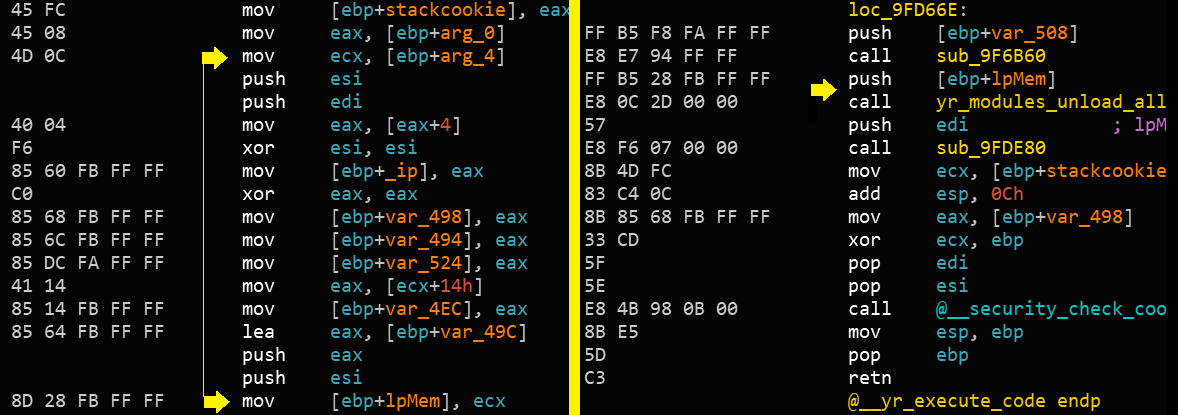
If I don’t want to find a gadget that skips that part of the stack (and perhaps even further back), I’ll have to fit my ROP-chain before that. That means I have 9 QWORDS at my disposal.
I accept that challenge
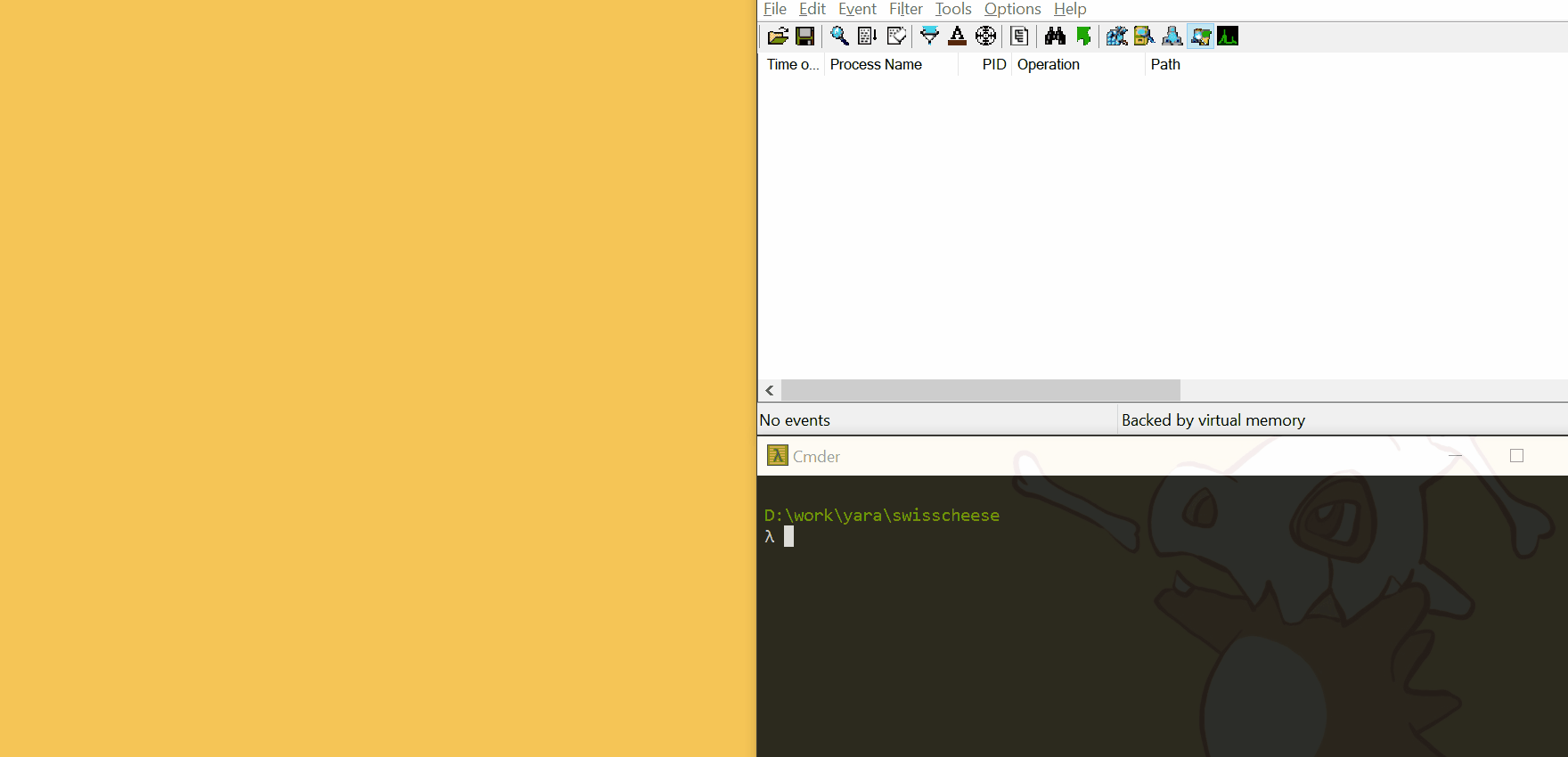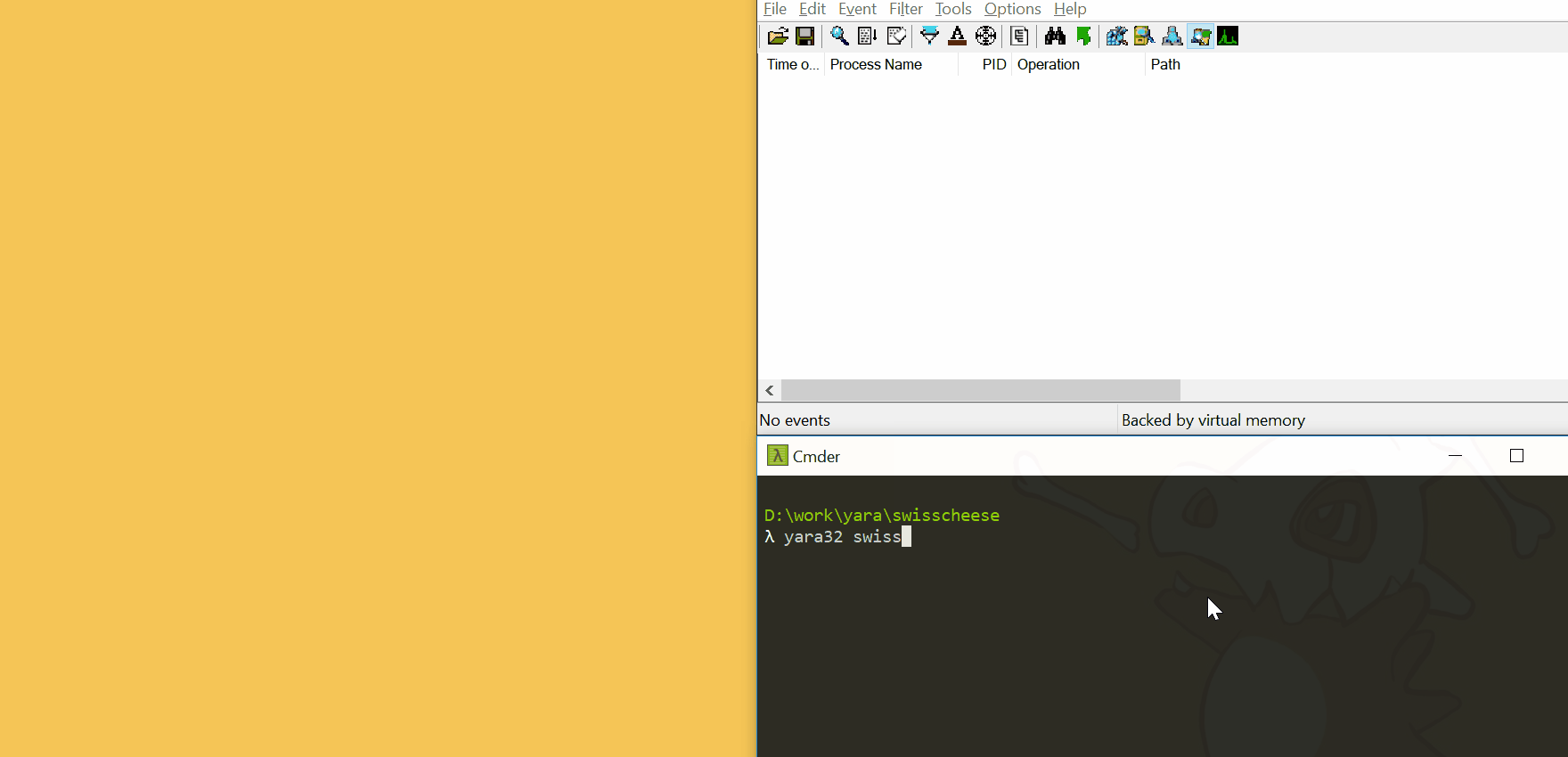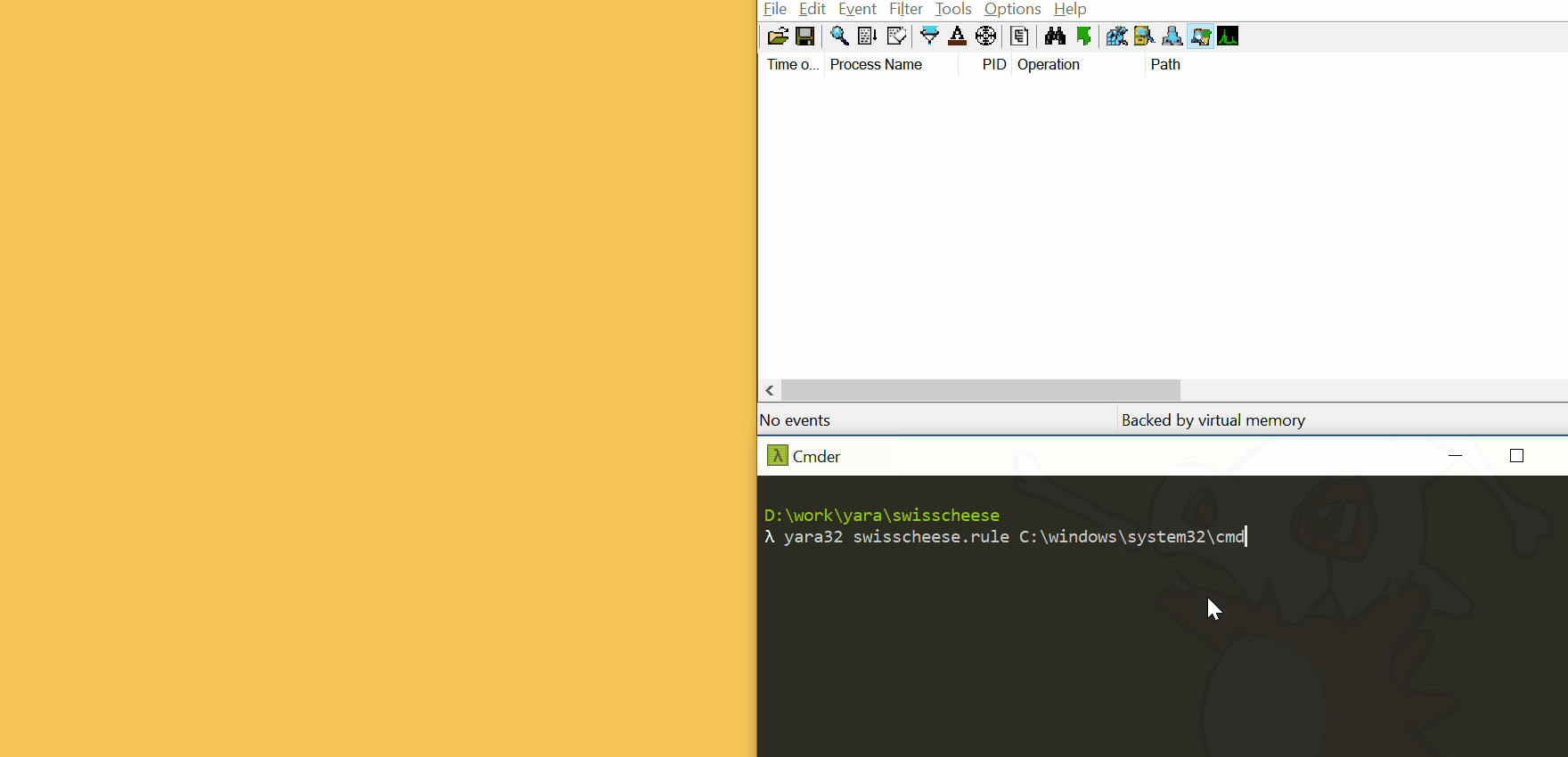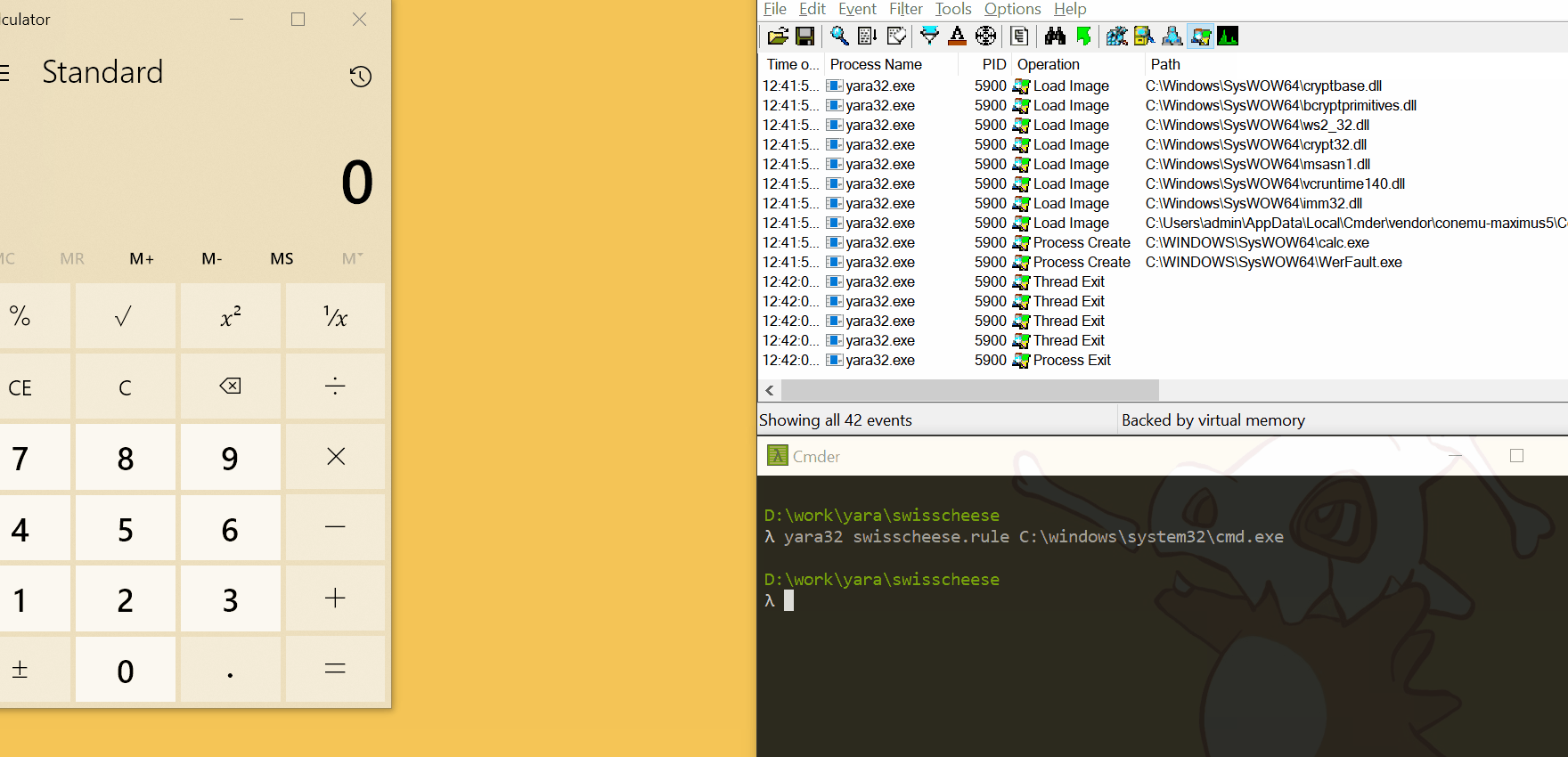
To run calc (as one does) I had to go the usual route of GetModuleHandleXXX and GetProcAddress. This meant:
- calculating the current base address of the module
- perform the necessary relocation for each gadget offset
- organize the stack with the required arguments
Where art thou?
Reading the return address is possible using OP_PUSH_M with the right index.
There is only one* function that calls yr_execute_code, so after the right shifts/bitwise-ands are performed
the base address can be calculated by using OP_INT_SUB.
Since the code is going to use that base address to relocate all the gadets, I’ll actually use the scratch memory as intended and save it for later use.
stdcall sure is nice
Thanks to the calling convention, I can set up some parts of the stack with the right arguments before the ROP even starts.
Immediate values were easy, the bytecode can use OP_POP_M to write them to the real stack.
However, in this instance I also needed to know the addresses of 3 strings:
L"kernel32"forGetModuleHandleExW"WinExec"forGetProcAddress"calc"forWinExec
YARA’s relocation to the rescue
If you haven’t forgotten, there was a pesky little feature in the file format - the relocation table. I can utilize it to relocate my bytecode operands to absolute addresses from relative file offsets.
All I need to do is have the offset to the string as my original value, and dump the string somewhere in the file (I chose to put them right after the code’s last instruction - OP_HALT)
Silent but deadly
To make things much easier (and allow me to fit the entire ROP in 9 contiguous QWORDS) yara wraps the entire function with try/catch by default. Once WinExec returns it will jump to some address from the stack (ironically, to context->objects_table) and exit silently:
YR_TRYCATCH(
!(flags & SCAN_FLAGS_NO_TRYCATCH), /* <-- this flag is not set */
{
result = yr_execute_code(
rules,
&context,
timeout,
start_time);
},{
result = ERROR_COULD_NOT_MAP_FILE;
});
Go go gadget(s)
I hand picked these gadgets to fit my PoC. I used some of them more than once.
Some of these required changing values in the yarasm file.
Attack vector
Any victim or service that allows running a user-supplied rule file without validating that it isn’t in binary format.
Validation is left to the user since, as of this writing, YARA does not distinguish between the two input formats and blindly accepts both8.
This should work regardless of the target file scanned9.
Mitigations?
- checking every access to scratch memory
- require an explicit flag to load and run a compiled rule
- check that every relocated
fointerdoes not point outside the buffer - make the loaded file read-only
*** update ***
For an in depth breakdown of YARA’s virtual machine and how the mitigations against this exploit can be bypassed go to part II.
Notes
- this research was done on 32-bit yara 3.7.1, tested on binaries from the official release page
- This was disclosed privately before being published
- This is what I do in my spare time, don’t judge me
- Follow the issue on github ↑
- read about YARA’s command line options ↑
- YARA’s C implementation, my python port ↑
- my incomplete template ↑
- 010editor ↑
- read about externals in YARA ↑
- YARA VM opcodes ↑
- The only difference between the two use cases is
When invoking YARA with compiled rules a single file is accepted. see 2 ↑ - PoC worked on
Windows 10when running against an executable or PID, it kinda works against a target directory ↑